WebAssembly: Beyond the Browser
Running WebAssembly as a Hyperscaled Edge Service


Hi again, I'm back. My previous blog post about my first journey into WebAssembly from September 2020 was picked up very well. I still see random mentions of it pop up from time to time, which I'm really happy about. I hope to have inspired a few readers to start playing around with WebAssembly.
Since then, neither I nor Micrio's development have sat still. Personally, I welcomed my new daughter WebAssemblina (not her real name) into this world. And the Micrio viewer client which my previous blog post is about has received a full rewrite, going from version 3.0 to 4.0. It's now using the holy trinity of WebAssembly, TypeScript and Svelte (which I will detail in an upcoming post).
This article is about another WebAssembly adventure: running it as a hyperscaled server.
Introduction
Besides being a zoomable image viewer running in your browser, Micrio is also the online platform behind it, having a dashboard where users can easily upload, enrich and publish their 10GB TIFF files to be used inside their own website. Micrio takes care of all hosting, image processing, and fast image delivery to the viewer clients.
One important aspect of Micrio is its full IIIF (International Image Interoperability Format) Image Server API compatibility, which is a web standard for delivering specific image crops and resizes with a specific rotation, color space, and file format.
At the start of this year, Micrio was used to display the world’s largest digitized artwork on the Dutch Rijksmuseum's website.
As you can imagine, using IIIF for this and requesting a high resolution crop from a 925,000 x 775,000px image, in grayscale, rotated 90 degrees, and as a PNG file, requires some processing power.

Like so
And what if there are thousands of such requests per minute? How can you deal with that without having a huge server farm running 24/7? And how do you get it to be blazingly quick as well?
This blog post is about doing this using WebAssembly, in the EDGE.

KnowYourMeme / MS / Punk-Rocker.com
(No, not that EDGE.)
The Edge
First things first. Like The Cloud, Edge Computing, or "The Edge" is a paradigm to describe a server call being handled as close as possible to the user requesting it.
I remember this being explained to me the first time: your local cell tower could be processing your phone's web request and send the response back to you.
Like, WOW. That idea alone is mind blowing. This would bring two huge improvements:
-
The end user would have their server response almost as quickly as physically possible, instead of waiting for network calls that could go back and forth across half the globe to return a very simple result.
-
The platform using this will be truly decentralized-- since the individual network request would theoretically not even leave the cell tower, which would be an incredible processing and networking improvement.
If this is a realistic future, in order to utilize this fully, server architecture needs to evolve. Because of course, you cannot deploy a full Docker container with your monolithic Frankencode 1.5GB Linux distro running a .NET app and SQL DB to a cell tower. It's not a fully fledged data center.
You would have to make a micro service that would do most of the heavy lifting. This means abstracting your server calls into the smallest possible single executable functions, which only need to be available during the request itself.
So think of it as a client web browser asking "What is 1+1?", which the local cell tower can handle by itself by running a oneplusone function that we wrote, and returning its result to the client immediately.
This is certainly not a new concept, as there already are AWS Lambda@Edge, Google Cloud Functions, Azure Functions, and many more providers that already offer these kind of functionalities.
Where Cloud Computing was a thing of the 2010s, I feel Edge Computing will be the next big thing in the 2020s: decentralize all the things  !
!
(On a related note, it's also of great value to the Web 3.0 paradigm.)
Cloud vs. Edge
Since Cloud and Edge are both fuzzy paradigms, they have a lot of overlap. For instance, a Content Distribution Network (CDN) used to deliver your streaming videos and music is an Edge service. What it does is put a zillion copies of an original resource all over the globe, making downloads fast and distributed.
But still, each location requires petabytes of storage and possibly heavy processing power.
In this article, I define Edge a little more sharply: not only serving server data from a source local to the user, but also doing this using micro services: a single-purpose, light weight server function that processes HTTP requests independently, without needing its own local infrastructure.
IIIF: Open Data standards for images and collections
The IIIF ("Triple-I-F", or International Image Interoperability Format) community is an international work group who have created an open standard for presenting high quality images and collections, backed by a consortium of libraries, museums, universities and more.
Their standard provides a very robust framework for any way, shape, or size you want to present your images and collections, making it easier to share them between platforms, and to make them more accessible to the world.
Micrio has been fully IIIF compatible since 2017. This means that the viewer client can be used with existing IIIF image collections hosted outside Micrio. Other IIIF viewer clients such as OpenSeaDragon can also view zoomable images uploaded to the Micrio platform (more info about this on the Micrio knowledge base).
IIIF Image API
For this article, I'll be focusing on the IIIF Image API: the standard focused on the delivery of image data to the viewer.
With it, as a user you can request any crop, in almost any output resolution, with an additional rotation, color format (color, grayscale or bitonal), to either a JPG or PNG output file.
This is done by using an URL scheme in the form of:
//your-server/your-image/{REGION}/{SIZE}/{ROTATON}/{COLOR_FORMAT}.{OUTPUT_TYPE}
So, for instance using the famous Night Watch painting mentioned above: https://iiif.micr.io/ERwIn/pct:.25,.4,.5,.2/1600,/0/color.jpg gives us a 1600 pixel wide resized crop of the view rectangle [0.25, 0.4, 0.75, 0.6] of the image, with no rotation, output as a color JPG file:

Here it is
Pretty neat, right? This means that no matter how big or small the original image is, this is a way of requesting an exact crop or resize to your liking.
And since this original source image is 925,000 x 775,000px, you can request insanely detailed crops, such as:

The eye of the middle character
How it works
If an image crop has to be made of an originally 4.5TB image, you certainly don't use the original source to do this.
When an image is uploaded into Micrio, our servers process it into a tile pyramid:
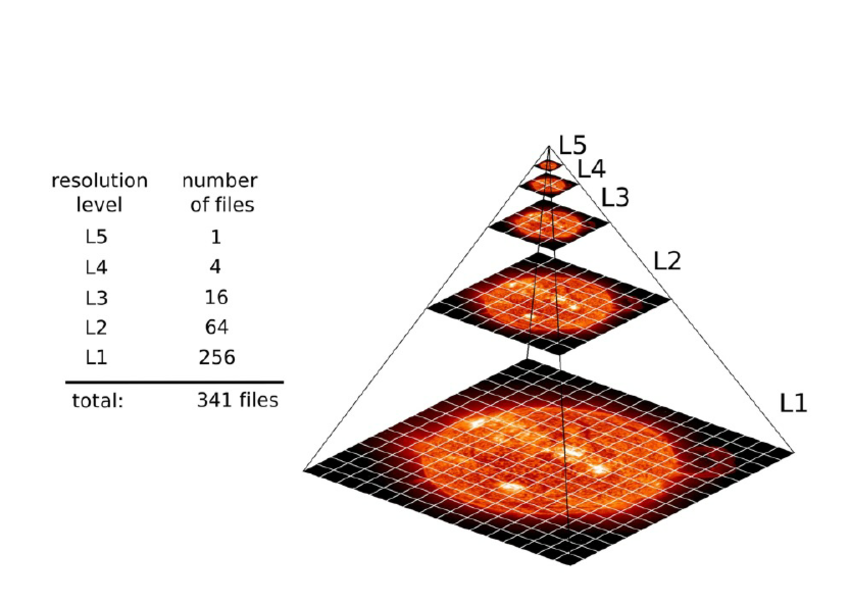
Which are just a bunch of image tiles per zoom level. These individual tiles are put into Micrio's cloud storage container.
What the IIIF server does when an image cutout is requested:
- Select and download the tiles needed for the requested view
- Stitch them together to a single RGB image canvas
- Apply any requested transform (rotation, color space)
- Encode it to the requested image format (JPG or PNG)
- Send that result as output
This makes it manageable, memory and CPU-wise, rather than working with the raw original file. It's not that heavy an operation.
Here come the CPU cycles
As you can imagine, offering a public image output API like this comes with a few challenges:
- The response should be fast: you don't want every request to take seconds.
- You only want to perform a unique image operation once: you don't want to re-do any operation every time a certain output is requested.
This has been how Micrio has been doing it: saving any previously generated crops, and simply returning a redirect to them whenever that crop was requested again. This works very well, and makes the server only do its image operations once.
But even so, it's possible that a museum has a collection overview page that has 100 thumbnails in a single page. Every non-cached visit of that page will generate at least 100 HTTP requests paired with 100 DB lookups with this server model. And in the worst case... 100 image generation operations at once!
So, for our large scale clients we created a separate proxy layer for all IIIF image requests inside their own ecosystem, preventing our server getting all direct traffic from their website visitors. It only receives new image requests, which is workable.
Growing pains
With Micrio growing its user base (yay!), so does the IIIF server utilization. Now, we serve multiple museums who have their own online collections and all use our single IIIF server endpoint. A plethora of requests end up on our poor image server.
Asking each of our larger users to install their own IIIF proxy inside their own hosting environment is not realistic.
Additionally, the main Micrio IIIF servers are located in West Europe. Meaning any IIIF server call from America or Asia already takes longer than necessary, since they cannot directly benefit from CDN functionality.
And honestly: as a techie, I'm too lazy to offer dedicated local IIIF servers to customers. I want to have a single solution that I can use for everyone!
(And work very hard to get there so I can be lazy later on!)
All in all, it was time for a rethink on how to do this properly. After some researching, moving this into The Edge seemed like a risky, but potentially very rewarding option: Could a micro service like that deal with our image operations? What are the limits of "micro"?
Making the plans
The 2017 Micrio IIIF server was written in C#/.NET Core 3.1 and has been running inside the 2-server load balanced main website at https://micr.io/ in Google AppEngine.
As image processing library, I used SkiaSharp, a .NET implementation of Skia, Google's Open Source high performance 2D graphics library.
This performed best compared to archaic .NET System.Drawing and other libraries, and with a bit of fiddling could be deployed to an AppEngine Flex container since it required a non-standard external dependency: an 8MB libSkiaSharp.so file.
Not that pretty, but it has held up very well for the last 5 years.
But it's just too heavy to use as an Edge function.
Enter Cloudflare
Cloudflare, and specifically their Cloudflare Workers platform, offer edge-based hosting with a big toolset of capabilities.
Cloudflare Workers are a single JS process, running inside their own JS V8 engine servers across the globe. So it's not a full node based server stack-- it's much more minimal, offering a basic set of JS APIs to work with as an input-output machine.
The code you deploy there will not run in a reserved VM, not on a single reserved CPU, but in a single sandboxed process in one of Cloudflare's servers closest to the requester, only being active during requests.
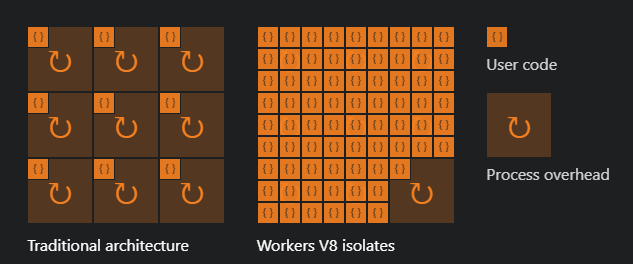
And the best thing?
THEY PROVIDE FULL WEBASSEMBLY SUPPORT!
This means you can write almost whatever code you want, to be executed by the Worker.
WebAssembly
For anyone unfamiliar with WebAssembly:
WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server applications.
Starting out as a way to run compiled code within a webpage at near-native CPU speeds, this has quickly proven useful to also be a powerful tool for server and Internet of Things applications, for a few reasons:
- It's a platform-independent, blind input-output machine
- Its low level instruction sets allow for maximum CPU performance
- It has a tiny footprint and runs in a sandbox of its own
- It's designed not to rely on any external libraries (though possible)
For our IIIF application, we're looking for lightning in a very tiny bottle. Using WebAssembly for this sounds like a good match!
The implementation
Okay, my favorite part: let's get technical.
Let's throw out all the existing C# code, Skia, the .NET SDKs, Google's AppEngine servers, and let's start with a clean slate.
We need three main ingredients:
- The WebAssembly runtime to do all the image operations
- The JavaScript program that takes care of all input and output (the glue)
- A way to run this as a Cloudflare Worker node
These need to work together, and on paper this is what they will have to do:

Our proposed program flow
Approach
Since WebAssembly binaries are platform independent, if you can get it to work in your browser, it also works when deployed as a server.
This means that we can do all development locally, without anything Cloudflare related. So for the first part, we can focus 100% on the WebAssembly and JS glue parts.
The JavaScript glue
WebAssembly by itself is totally blind and cannot run independently: it needs some form of input-output to be able to work. So, in the web browser, your program needs to have some JS code which acts as glue, to connect your Wasm code to your browser.
In our case, JS needs to take care of a few things:
- Loading and instancing the
.wasmbinary - Parsing the input IIIF query string and doing any syntax error checking
- Getting the original image data such as resolution from the internal Micrio API *
- Selecting and downloading the image tiles required for the requested view, since WebAssembly doesn't have any HTTP awareness
- Passing the downloaded raw tiles into WebAssembly, placing them on a virtual output canvas
- Getting the JPG or PNG encoded output image bytes back from WebAssembly
- Returning this image back to the requester
* There is (of course) a centralized Micrio API containing all individual image metadata such as original resolution, required to get a correct IIIF cutout. However, this data is cached on the Cloudflare side, so this API call is only made once per Micrio image: 1,000 different cutouts of the same image will only generate 1 Micrio API call.
This is quite straightforward, and for the rest of the article I will refer to this as this JS(/TS) function:
async getIIIFImage(iiifQuery:string) : Promise<Uint8Array>
WebAssembly: finding the right language
One of the best things about WebAssembly is that a wide range of programming languages can compile to a .wasm binary. So being at the start of a project gives you the freedom to pick your favorite.
In my previous article, I created a WebGL engine, which is purely mathematical and doesn't need any external libraries. For that, I used AssemblyScript, because it closely resembles TypeScript. This was fit for the job and still works perfectly.
But now, we will have to do actual image operations: I need libraries to account for JPEG and PNG decoding and encoding, and have to be able to do image scaling, rotating, and color operations.
After researching for a full five (5) seconds, I settled on... C!
(Editorial note: actually it was Rust. Long story short: I had it working, and it ran in production for five months. But in the end it didn't fully meet my needs anymore (WebP output support), so I redid it in C, and will continue this article pretending like this was my first choice.)
In comes the OG
I never wrote a line of C code in my life. When I was younger I hobbied around with C++, and when I was older this professionally became C#. But this was the first time to be working with the original C (turning 50 years old this year 🎉)!
The setup
The already established emscripten is great for compiling C(++) projects into WebAssembly for your browser, including generating an oftentimes quite large JavaScript glue file so it will run inside your browser without any extra work.
But since I already had all inputs and outputs defined, I didn't need a generated glue file. I was looking for a simpler way to compile my .c files into a barebone .wasm file.
Then I stumbled upon WASI (WebAssembly System Interface): a compiler for using WebAssembly independently from the browser. Compiling your code into WebAssembly using clang and llvm, providing a minimal set of independent external functions (like <math.h>) .
With this, a helloworld.c could compile to Wasm, and would run inside the browser as a raw WebAssembly instance, using self made imports and exports in JS.
The 1990s called
For our program, we cannot rely on any external image functionality like reading and writing JPG and PNG files. So I need to include these libraries in the codebase that will compile to WebAssembly.
And since most of the world runs on C, this was amazingly pretty easy: I could use libjpeg-8c, libpng-1.6.37, and zlib-1.2.11 (required by PNG) libraries in their original forms!
With libjpeg and libpng, I first had to run the ./configure command after downloading the sources, generating all required headers, but then I could already reference it from my own code and even compile it along with my own code to an OS-native a.out binary, which clang compiles to by default.
For WebAssembly, some minor tweaking was required in the form of removing some hopefully non-crucial external references that WASI doesn't offer, keeping only the very basic std references which WASI provides for. With that done, miraculously, it compiled to WebAssembly perfectly!
Can I just say:
HOW 𝓕𝓡🤯𝓖𝓖𝓘𝓝' AWESOME THAT FELT!?
This wasn't just standing on the shoulders of giants, this felt like running along with them! How crazy it is to write a program for 2022 tech, in a language from 1972, including code originating from 1991, 31 years ago!
You don't get any closer to the CPU than that. (Or can you...)
I was excited as a drunken toddler seeing it come to life in my browser.
Image operations
Now being able to read and write JPG and PNG formats, I had to generate the actual output image.
Where SkiaSharp offered very convenient placement, rotation, and color space functions, this time I was completely naked.
All I had were the decoded individual image tiles as RGB memory buffers, and the final output resolution, so I had to find a way to place and scale the individual tiles on their correct pixel locations in an output canvas.
Which, if you think about it, really isn't that difficult: a single pixel in an RGB image takes 3 bytes in a memory buffer: [R, G, B]. And if you know the X and Y position of a pixel, you can calculate where in the memory buffer this pixel is stored.
Using that knowledge, you can just fumble some pixels and pixel rows around using a lot of memcpy operations, resulting in for instance this scaling function:
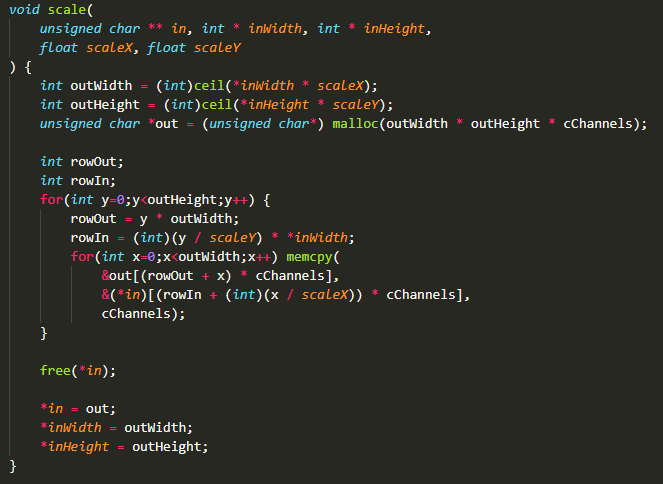
C veterans must be laughing at this but I don't care!
So I ended up writing all image operations (scaling, placement, rotation, and RGB<>grayscale<>1-bit color operations) by myself.
350KB of raw power
"Neat!" 📸
Bender
So with all code in place, we can now compile to a iiif.wasm file:
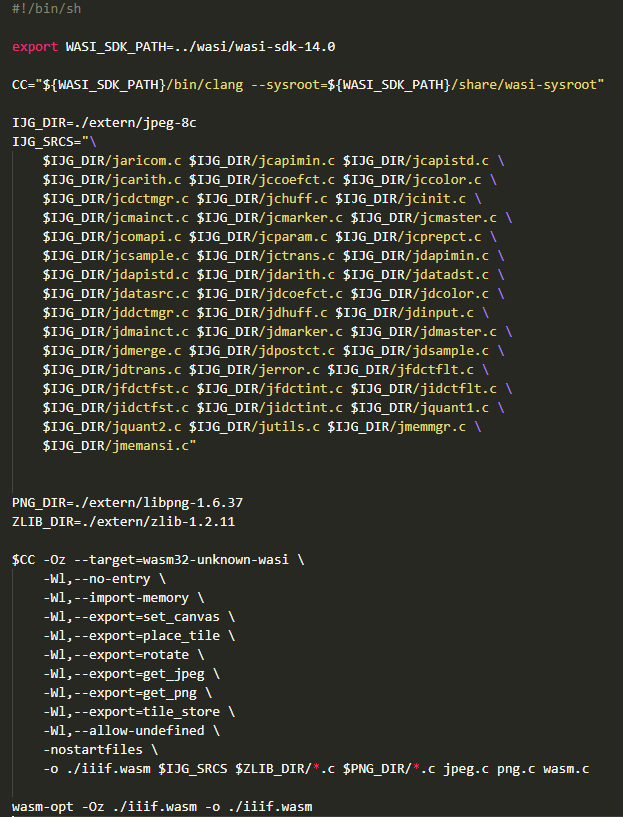
The build script
Resulting in a size-optimized (-Oz flag) file of 350KB which does everything I need, without ANY external dependencies.
Quite a difference with the 8MB libSkiaSharp.so (-95%)!
Now all what's left is bundling it together and getting it to work.
Running it the browser
Since we now have our compiled .wasm file and the beautifully written one-liner JS getIIIFImage(), we can combine and load it.
Getting the imports right
A crucial thing for loading WebAssembly in JS is the imports object containing our C code's imported and exported function definitions, and any shared WebAssembly.Memory you want to give your Wasm program.
In my case, some WASI-specific default exports based on the compiled C code had to be included. These were some file related operations, which I could just set as empty functions. I bet if I start trimming the included C libraries, these can be cut away.
In the end, I ended up with:
const imports = {
"env": {
// The Wasm runtime shared memory, 5MB is enough for us
"memory": new WebAssembly.Memory({initial: 5*16}),
// Function called from inside Wasm to specify final output image size in bytes
"set_size": (num) => { this.fileSize = num; }
},
"wasi_snapshot_preview1": {
// These are all unused empty functions, but required by the Wasm binary
// 'fd_seek','fd_close','fd_write', 'environ_get', 'environ_sizes_get', 'proc_exit'
}
}
Using that, we can instance our program in JS as such:

Loading Wasm in your browser
Breaking the ice
And that's it! Then wasm.exports will contain the exported and callable functions from your C program.
Trying it out in the browser, sending in a IIIF query string resulted in a memory pointer and length in bytes from our WebAssembly program in our shared WebAssembly.Memory, which can be read out as a JS Uint8Array.
Then to preview it locally, we can use URL.createObjectURL() in our browser to print it as an HTML image:
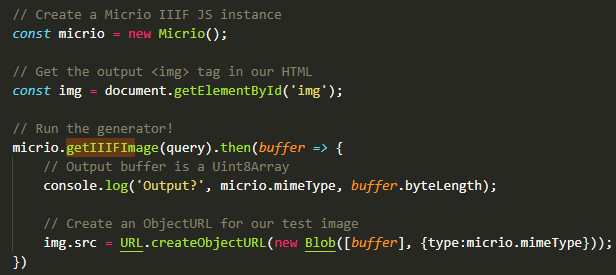
Directly view the WebAssembly output as an image
Perhaps a bit anticlimactic, but ☝ this actually works! Any cutout can be made of any Micrio image, and it's all done inside the browser!
🇳🇱 👋 Hey Dutchies!
Even tussendoor... we zoeken nieuwe Q'ers!
Going live
So, we've got everything set up and running in our browser. Now, we need to get it to work inside a Cloudflare Worker. Luckily, that's not hard.
The HTTP handler
Cloudflare Workers offer you a lot of standard JS APIs for you to use as you wish. Basically their helloworld.js for a HTTP server is:
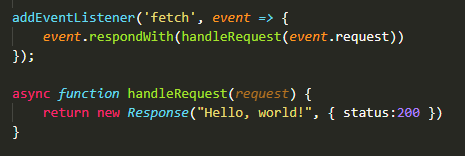
Cloudflare Workers' Hello World
This can easily be deployed and runs out of the box. Now, we can simply add our JS glue code to this, and make the handleRequest function to use this:
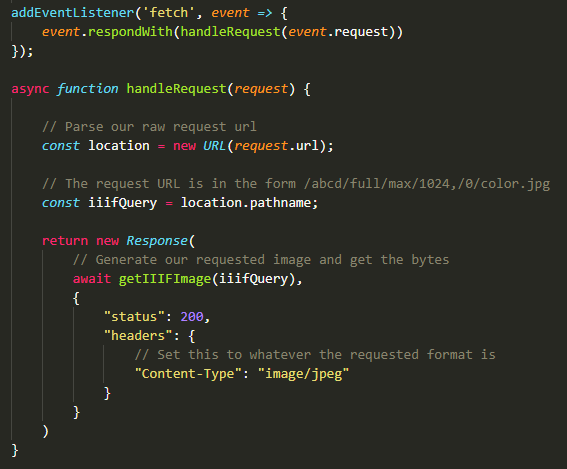
Our working HTTP handler
WebAssembly in Cloudflare Workers
For the .wasm binary: Cloudflare offers full support for this. Set it up by opening your wrangler.toml file and add the wasm_modules line containing a reference to your file:

This will give us a global variable WASM in our JS, which is an already loaded WebAssembly.Module! So, no need to do any .wasm file loading or anything; Cloudflare offers it to you ready to use.
Caching the output
The only difference between the server and client version of our code, is that we want to cache any previously generated IIIF output within Cloudflare, making sure every image generation is only done once, and afterwards the initial version is served.
For this I use Cloudflare KV storage: a very basic key-value storage, offering binary blob storage to blobs up to 25MB.
When a new IIIF image has been generated, before sending it back to the client, we put it into the KV storage bucket, using the original IIIF query string as key.
Then, for any new request coming in, we first check if this image has already been generated, and if so, immediately return that blob, bypassing the entire generation process.
In the JS code, adding this caching functionality was only two extra lines of code.
The result: a Smart CDN
While the caching layer is only a small mention, behind the scenes this is responsible for most of the scaled performance of our service. The KV Storage service makes sure that its stored blobs are locally available to wherever the request comes from, acting like a CDN.
But with our added WebAssembly power, we have now basically created a CDN with built-in IIIF image processing.

This is part of the magic at Cloudflare: as a developer, I don't (have to) care about how they do it.
Their slogan "You write code. We handle the rest" has proven true to me since I started using them a year ago. What they have there is very impressive: their documentation, examples, tone of voice, and often newly released (beta) features are music to my ears. Micrio has multiple projects running there in production, so far with zero problems or downtime. (Cloudflare, if you're reading this: BIG FAN!!!1)
Limitations
So, with all this good news, where is the "...but"?
Since Cloudflare workers are essentially made to be light-weight, a Worker is limited to 30 seconds of CPU time (in their paid "Unbound" model), and 50 underlying HTTP requests.
This means that requesting the 925,000 x 775,000px image as a full-sized PNG probably isn't going to work.
The IIIF specification already provides for this: following their standard, our server can return a HTTP 400 error when the output pixel size exceeds the server's limit.
So now it's up to us to define those limits.
-
Since we're limited to 50 underlying http requests, and the default Micrio tile size is 1,024 x 1,024px, this means we can request a most of
1024 * 1024 * 50pixels, or a total surface of 52.4 megapixels, which is a maximum of 7,240 x 7,240px. However, this would have to be a perfect fit with each tile at 100% of its original size. In reality, the crop will have a lot of tiles cut off at the edges, and tiles can be scaled 50%-100% of their original size, so it's possible the 50 tiles are already needed for (an even perfectly cut off) 3,690 x 3,690 at 51% scale. -
Additionally, a 25MB limit exists for the Cloudflare KV storage. That means a generated output image should be smaller than that. A full color RGBA PNG file of around 4,500 x 4,500 will already take about this much.
-
Lastly, there is the 30 seconds CPU time limit. On this one, I can say that staying within the above limits, I haven't reached this limit by far.
After some trial and error, I've limited our IIIF operations based on the requested image type:
| Type | Maximum resolution | In MPix |
|---|---|---|
| JPEG | 4,096 x 4,096 | 16.7MPix |
| PNG | 3,584 x 3,584 | 12.8MPix |
Which well exceeds any requests we regularly receive: we can work with this!
For users wanting larger crops, there are a few alternatives, such as running our iiif.wasm in their browser, which is only limited to JPG/PNG's own resolution limits. For the few cases that need this, we're offering access to it from Micrio.
Performance
So, how fast is Cloudflare?
Pretty fast.
| Requested resolution | Tile download time | JPG time, size | PNG time, size | Full reload time |
|---|---|---|---|---|
| 3,584 x 3,584 | 6.2s | 1.8s, 2.5MB | 6.8s, 24.9MB | 1.1s |
| 2,560 x 1,440 | 3.8s | 0.7s, 954kB | 1.8s, 8.6MB | 540ms |
| 1,920 x 1,080 | 3.3s | 0.4s, 488kB | 1.0s, 4.7MB | 500ms |
| 1,024 x 1,024 | 1.1s | 0.3s, 235kB | 0.5s, 2.3MB | 93ms |
| 512 x 512 | 0.8s | 0.1s, 63kB | 0.2s, 598kB | 57ms |
The tile download time is the time it took for the Worker to download the individual image tiles. These can vary a lot based on the number of tiles required and on the geographical distance between the individual Cloudflare Worker (East Asia, in my current case) and Micrio's main storage bucket (Western Europe).
The next columns are the raw processing time it takes to generate JPG and PNG files and saving them in the Cloudflare KV.
Since all unique image generations are only carried out only once, reloading a generated URL (with cache disabled) yields very acceptable response + download times.
That's.. not very impressive?
Waiting 13 seconds for a 12MPix image generation? Get out of here...
Thanks to the world of exponentials (a 3,584 x 3,584 image has 59 times as many pixels as an 512 x 512 image), what seems like a pretty low resolution actually can be quite heavy. To provide some comparisons, here are the same image jobs carried out by our previous C# implementation, running locally on my pretty high-end laptop:
| Requested resolution | JPG time | PNG time |
|---|---|---|
| 3,584 x 3,584 | 0.5s | 5.5s |
| 2,560 x 1,440 | 0.3s | 1.6s |
| 1,920 x 1,080 | 0.1s | 0.9s |
| 1,024 x 1,024 | 0.02s | 0.51s |
| 512 x 512 | 0.005s | 0.131s |
What I've timed here is only the JPG/PNG encoding -- the pure CPU work. It's faster than our Cloudflare Worker, but not by so much!
Geographical dependencies
Another influence on generation times is the physical distance between the storage bucket containing the original tiles, and the Cloudflare Worker node downloading them. The further away they are, the longer it will take to download all necessary tiles.
HOWEVER. Micrio supports custom storage buckets for its larger users. Meaning, that some US-based clients have their own Micrio image storage bucket located in the US. In these cases, US-based requests to the IIIF service will yield underlying tile downloads from their US-based storage, by the US-based Worker node.
Which means that for US-based visitors, it will feel like a local server with optimal download times. And for international users, after the initial image generation, download times depend on Cloudflare's KV storage propagation (which is very good).
Concluding
Phew, that was quite another adventure.
In real time, this article describes about nine months consisting of lazy on-the-side development, a testing period, five months of totally stable runtime, and a rewrite from Rust to C after WebP support was requested.
The most important target has been reached: Micrio now has a fully scalable IIIF Edge-based service, which is ready to serve global traffic. The original C# servers can now be turned off.
Secondly, it was A LOT OF FUN to create this. I still can't get over having my own C code running as a production service. It was a mostly happy flow-based development process, and it has really opened my eyes more towards how future web projects can be done.
If you are a developer, I can really recommend taking a few hours to create your own Hello World WebAssembly application, be it inside your browser, or immediately as a server component using WASI.
Looking forward to the future of WebAssembly & everything in the Edge.
Thank you for reading!
Acknowledgements
Thank you, Jiri, Maurice, Lotte & Erwin for your proofreading and feedback!