The beautiful headache called event sourcing
A deep dive into the decision to use event sourcing for payment processing and why, in the end, it was a wonderful fit



Payment processing is important to get right. You don’t want to disappoint people giving you their hard earned money. Payments are hard to get right as well. Promotions, cancellations and chargebacks all have to be taken into account. When launching on multiple platforms, it becomes even more complex due to different payment services that are involved. How to get all of that complexity under control?
For our most recent payment implementation, we decided to use event sourcing. Getting the implementation right gave us some headaches, but the end result was rewarding nonetheless. We’re not here to convince you that event sourcing is the best invention since sliced bread. Neither are we trying to scare you away from it. This is the honest, detailed story about how we implemented the payment processing for Primephonic, the streaming classical music startup, using event sourcing.
Read about why we picked event sourcing as our solution, how we implemented it, what worked great and what was hard to get right. It was one of the most educational projects we’ve done in quite some time.
Why we started looking at event sourcing
There was a payment processing backend up and running for Apple subscriptions only, but it was hard to inspect what was going on when customers reported issues, let alone to make a correction. We also wanted to expand to web-based subscriptions using Stripe and support Google Play Store subscriptions. Expanding the current system was not the way to go: we needed a new system with more control and insight. We were going for a minimal implementation at first and planned to iterate on the implementation to add more features later.
So our new service should take all payment information that Apple, Google, and Stripe push to us as input. Based on this it should decide whether a user should have access, on what plan the user is and write that conclusion towards our user database.
We use Auth0 as our user database. Every application - Primephonic is available on iOS, Android, web, and Sonos - connects to Auth0 to allow users to log in. Also, when a user signs up, an Auth0 rule gives that user a trial product and writes this to the user's metadata. All other apps and backend APIs can check whether the user has a valid product by checking the JWT token that Auth0 provides. Some of the apps also check whether the user has a trial and should be presented with banners to buy a subscription.
The new service we wanted to create is our source of truth for the metadata fields in Auth0. In normal operations the APIs and apps don't directly communicate with that backend, instead they read the metadata fields from the Auth0 JWT token. Only when buying a subscription the apps do a few API calls to this subscription service to process the payment. This allows us to replace the backend system relatively easily if needed.
Payments deserve a transparent approach
One of the first insights we had was that our old payment processing backend didn't keep the data on trials. The cron job we had running to check for expired trials didn't correctly check for an existing Apple subscription. We also had a bug in the code that was handling notifications from Apple. The initial version wasn't checking some fields that had to do with grace periods. So it was a little too eager to remove the rights to a product from the Auth0 metadata for some users.
This all resulted in a confusing situation where we had no idea why fields were removed, there was no trail, the initial implementation didn't have the appropriate logging in place. Another thing that was bugging us, was the fact that once the user had bought a subscription, we would delete the field that contained the trial end date. We were throwing away valuable data! Should the user cancel their subscription, we couldn't even fall back to the trial if it were still valid.
We needed a more transparent approach. Storing some user-specific data in Auth0 works well for integrating with the other apps and APIs, but we didn’t have any idea how we could conclude that a user did or did not have one of our plans. What we needed was a separate system that we could use as a source of truth for the subscription of a user.
Event sourcing versus a simple database
One of the options was to use a simple relational database that had a table for the user and one for its current subscriptions. If something changed for a user, we'd compute a conclusion and write that to the user's Auth0 metadata. We wouldn't delete any subscriptions, just mark them as canceled. The code that would update Auth0 would filter everything out that was expired.
We already knew things would get more complex once more subscriptions and payment providers would be supported. We could, for example, misinterpret the documentation from one of the payment providers, as happened with the grace period in the first version. So to maximize our abilities to recover from bugs and to implement future features with historic data, we wanted to store more information than strictly necessary for the first release.
Storing more information than you need poses a new question: where do you leave all this data? Logging is not the right place, because we won't retain that data for long. And accessing it in the application code is a nightmare. So we thought of a good old friend we've used on a few projects: event sourcing.
Advantages of event sourcing
Event sourcing seemed to be the perfect fit for this subscription backend we needed to build. We had structured events coming in from our iOS app and Apple's notification system. We also wrote an Auth0 rule that would send data about the user to the backend, namely the trial end date, but we sent a bit more context like the moment of registration. We felt these fields could be useful in the future or while debugging.
One thing we quickly figured out was that we also wanted to store responses to API calls from external sources. We couldn’t rely on external APIs to reproduce all data they have ever given us. For example, when we receive an Apple payment in the backend we need to call Apple's APIs to get information about the payment. We stored that data in the event as well as the notification message, so we would be able to rebuild all our state in the database, just by looking at the events even when Apple decides to remove some historical data or change around some fields.
That's right, we store events and process the data that is inside them, without pulling in any other external data while we process. This allows us to fix bugs and just pretend we did it right in the first place. The proper terminology here is the ‘projection’ of the events. Rebuilding the projection is a matter of creating a new schema (we're using PostgreSQL as our database), applying all database migration scripts to get all the tables and indexes up. Then we apply all of the events onto that fresh projection with the new code that has the bug fixed or an added feature. Rebuilding a projection on a local machine can also help out with debugging.
This has made us feel that event sourcing is a good fit for payment processing and subscription management. Never deleting the source data and good logging make it possible to explain exactly what has happened and why. Even if something turns out to be wrong because of a bug we can fix it and rebuild the conclusion based on the data we have.
Disadvantages of event sourcing
To get all of this up and running is not as simple as you might think. In the end we're more or less rolling our own database, not a trivial task.
One of the downsides of event sourcing is that it's more complex than just doing a database update. You need to make sure that you store all the information to replay that event. One way to do this is by separating the storage and processing of the event. Doing this helps to make the system more resilient to failures. Our apps and Apple’s webhooks get a response once the event is stored successfully and ready to be processed later on. If storage of the request fails, an error will be returned so Apple can retry calling the webhook later on. Once their request is safely stored it will be processed at a later time.
This practice of storing the events and separately processing them makes it a so-called ‘eventual consistent’ system. Our service will acknowledge that the event was stored safely, but further processing into the projection and, if applicable, updating the Auth0 state is a different step that is separated by a queue. The apps don't know exactly when this processing is done.
Sometimes we need to get around this, especially when the user makes a payment and wants to know if it’s processed and they can start listening to music. To make this possible every endpoint that creates an event when it's called, returns the identifier of the created event. The client can then poll another endpoint to check whether the event identifier has been processed and written to Auth0. As soon as that is the case the subscription is activated and the user can listen to music!
This same eventual consistency, as often found in CQRS-like systems, was even trickier to guarantee when we added Stripe payments for our web users. Stripe has a terrific webhook system which is more than enough to process every payment made for a subscription. However, the web app that handles entering the credit card details only sends a confirmation to Stripe, so our subscription backend doesn't receive the event identifier it can poll for. But the web app also needs to know when the subscription is activated so it can refresh the JWT tokens and tell the user everything is ready to go. We pragmatically solved this by letting it poll the subscription backend to see if something changes.
One other thing that's important in an event-sourced system is that you have a firm grip on the order in which events are processed. If you need to rebuild the projection, you might get different results if the sequence is different, leading to erroneous conclusions. We chose to enforce a very strict order of events by using the sequence id of a PostgreSQL table. That way, once an event is saved into the database, its order is set.
Now that we’ve explained why we chose for event sourcing with an eventual consistent setup (to increase resilience to failures), it is time to give an insight in how the system was built.
Our event sourcing implementation in Serverless
Directly from the start we decided to use small easily testable AWS Lambda functions implemented in TypeScript that communicate mostly via queues. Since this is a payments processor, it makes sense to use a serverless model to lower costs and maintenance. There will be times this service is not used, while at other times there will be a number of users subscribing or renewing.
Deployment is done by Serverless, a handy framework to deploy lambda functions. Serverless itself uses CloudFormation templates to create resources. It saves you from having to set up a CloudFormation template yourself. It also has a lot of plugins to make life easier. When the setup became more complex we needed to dive a little deeper into plugins and how CloudFormation works, but the head start it gave was worth it.
Lambda works great with NodeJS, which we love. It wasn't that hard to set up serverless-webpack with TypeScript. TypeScript proved to be invaluable for us for strictly expressing what data we handle in the type system, which prevented a lot of bugs and makes reasoning about this system way easier to do.
Putting all the lambda’s together
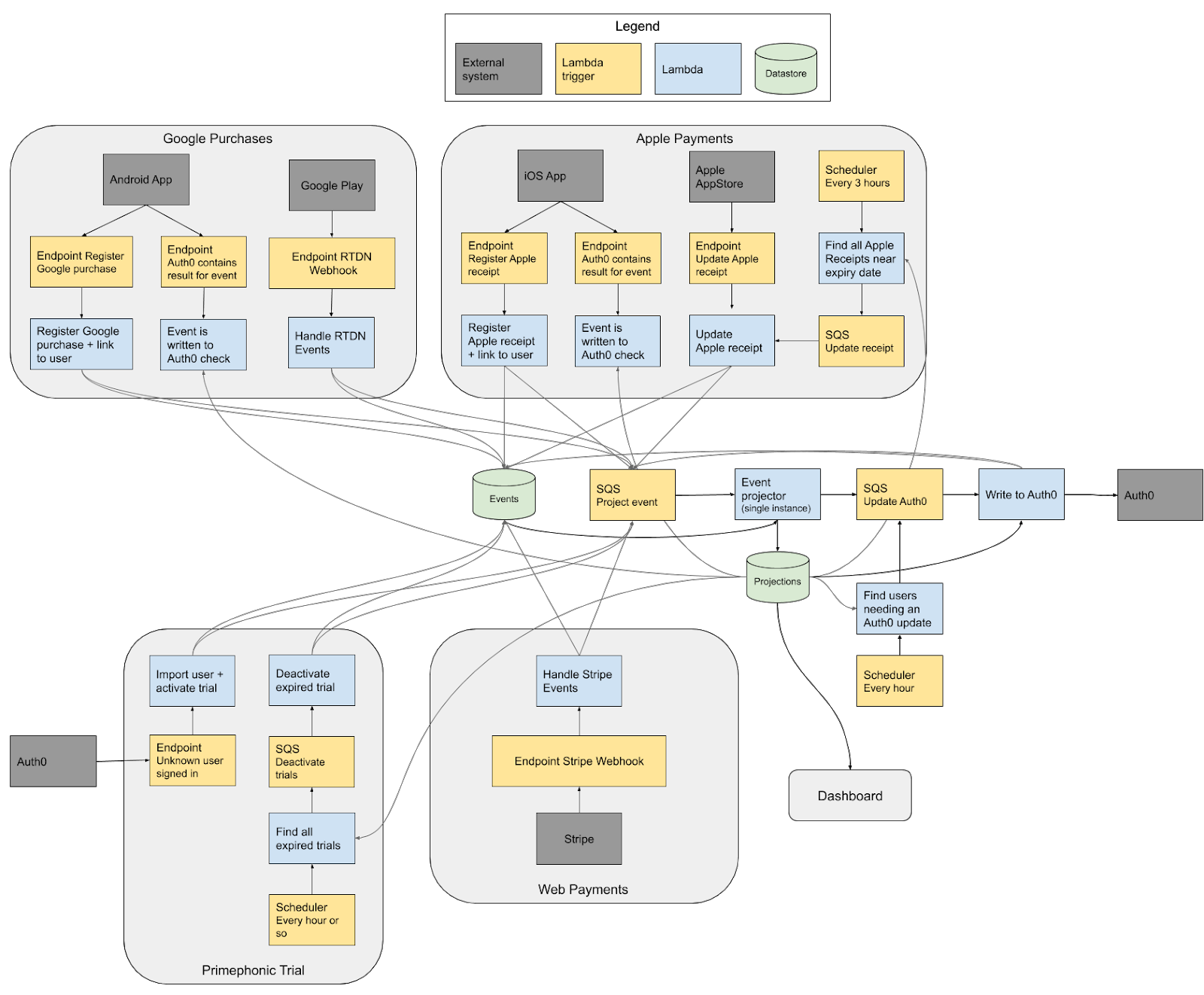
Let's take a look at the center part of the diagram, the core of the system. All lambdas that handle incoming API requests or cron jobs can write an event into the event table. This is a simple SQL table in the PostgreSQL database. The table has a serial id column, a date field, and a data column. We chose to use the JSONB data type which works well.
After an event is written we use another lambda, the ‘Event projector’, to process events. The lambda is triggered by an SQS queue. All the endpoints and the cron job handler insert a message into this queue after they write an event in the database. When the event projector handles items from the queue, it processes a batch of events that haven't been processed. If there is no new event to process, the event processor just ignores the events that were already processed.
The serverless YAML for this event projector function looks like this:
runprojection:
handler: src/handler.runProjection
reservedConcurrency: 1
timeout: 30
events:
- sqs:
arn:
"Fn::GetAtt": [ RunProjectionQueue, Arn ]
batchSize: 10To keep things simple, we make this processor a singleton by setting the reserved concurrency to 1. Reserving concurrency does two things. First of all, it ensures that this lambda will always be able to run. In AWS Lambda you can have a maximum of 1000 lambdas running concurrently. We reserve some concurrency to make sure it can always be started. Secondly, this reservation also caps the number of instances of this lamba that will ever be active at the same time (in our case 1), effectively making this a singleton.
The batch size is set to 10 to reduce invocations. If 10 events are inserted in a short period, the lambda will execute just once and process all 10 events in one invocation. If processing an event fails for some reason, e.g. a database connection drops, the redrive policy of the queue makes sure it's attempted 3 times. And even when any database hiccup takes longer, any new event coming will trigger a batch of events that need processing. This seems to be quite a solid setup in practice. We haven't seen a big latency in event processing.
While processing the event in this event processor, we update the same SQL database. We just write the changes to a separate schema called ‘projections’. This separate schema helps to rebuild the projection with almost no downtime when we need to fix bugs or add features that require us to reprocess the old events in the database.
Most of the events affect the state of a user's subscription. If this is the case the processor inserts a message into another queue that invokes the ‘Update Auth0’-lambda. This lambda makes sure the state change is represented in Auth0, so that all clients are aware of the change.
Updating Auth0 from a lambda
One field that we write to Auth0 has been proven to be very useful when debugging issues: the ‘based_on_event_id’ field. It holds the latest event identifier that triggered an update for this user to Auth0. It gives a great starting point to trace back what information and event are used to reach to the state that is used by the clients.
If for some reason, updating Auth0 isn't working, we first retry by utilizing the SQS queue's RedrivePolicy. But if Auth0 is down for a longer time, messages from the queue will end up in a dead letter queue. That would mean the Auth0 metadata was not updated for this user and their subscription is not updated correctly.
To be able to recover from such downtime, we store the identifier of the last event that was successfully written to Auth0 in the projecten. Of course, this in itself also needs to be done by firing an ‘successfully written out to Auth0’-event. So everything is consistent, once you rebuild the projection.
With this information, we can detect failed updates by comparing the ‘successfully written out to Auth0’-event identifier to the event identifier that got us to the latest subscription state. This makes recovering easy, we just trigger the ‘Update Auth0’ lambda for each user where those events are not the same.
Detecting missed events
This describes the core of this event sourced system. One thing we didn't add to the architecture diagram was a scheduled lambda that helped us to detect whether we missed any events. For every event we process, we insert a record into the projection. This lets us detect if we have missed events or events that were processed more than once. It also allows us to measure the latency between inserting the event and finishing processing it.
Running into real issues
In any complex system you run into problems, and so did we. From testing the whole system to rebuilding the projection, we faced several challenges. Read on to learn more about these real-world challenges of event sourcing.
🇳🇱 👋 Hey Dutchies!
Even tussendoor... we zoeken nieuwe Q'ers!
Queues make testing hard
The most challenging thing we encountered, was our choice of SQS to chain everything together. Using queues makes all the lambdas smaller and easier to test. But testing the system as a whole is rather difficult. To make debugging a bit easier, we mock out the queues. In our integration tests, the queues immediately call the function that handles that particular message. This makes testing whole scenarios easier. For example, a scenario can be simulated where a user subscribes, renews and then cancels her subscription. The test can then assert that the access to the product is revoked.
Rebuilding became slow
When we started we had a small number of events, so rebuilding the projection was fast, taking just under a minute. As we progressed, we ingested more and more events and rebuilding took longer and longer, up to the point where the lambda rebuilding the projection would time out.
We had to make a lambda that would process a limited number of events and then call itself. To do this, a message was added to the queue to ensure that the process will continue.
In hindsight, we shouldn't have relied so much on our transactional SQL model for the projection, because it slows the processing down too much. Using the database for everything is straightforward, since it enforces you to use the correct identifiers and other data integrity at every step, but we could have done it without using the database. If possible, in-memory processing of the events and writing the final results to storage is preferable. This probably would've required us to set up our code somewhat differently, but it would have been worth it since faster rebuilding gives a lot of agility in developing the system further.
Database transactions caused skipped events
We mentioned the scheduled function that checks we didn't miss any events. Well, that went off pretty quickly. As you might remember, we have several functions inserting events and a singleton function that reads batches of unprocessed events. They’re all doing their work in parallel.
Let's say that two separate API calls occur around the same time. Both result in inserting an event into the database. Right after one of the events is inserted, the singleton function starts to read the database to update the projection. The other event takes a bit longer to write, as shown in the diagram below.
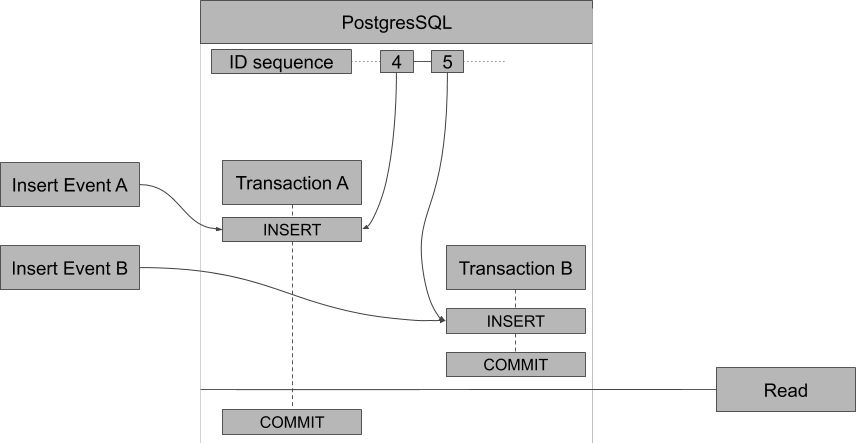
The diagram shows the two inserts in transaction A and B. Transaction A starts a little bit earlier than transaction B, but for some reason it takes a little bit longer to fully commit to the database. When transaction B is ready, it asks the projection to be updated. So the singleton is reading from the event table (indicated by the Read block to the right in the diagram):
SELECT …
FROM event
WHERE event_id > ${lastProcessedEventId}The singleton will see that event 3 is the last processed event and it will do a `> 3` query. The database will now only return event 5 since event 4 isn’t committed yet. So event 4 is skipped. The next time the singleton runs, only event 6 and further will be processed.
The fix was to take a lock when reading. That means that any transaction that is writing to the database must finish before we start reading. When we're reading we can't write events. Writing must wait until reading is finished. This fixes the problem, but also makes inserting and reading events somewhat slower.
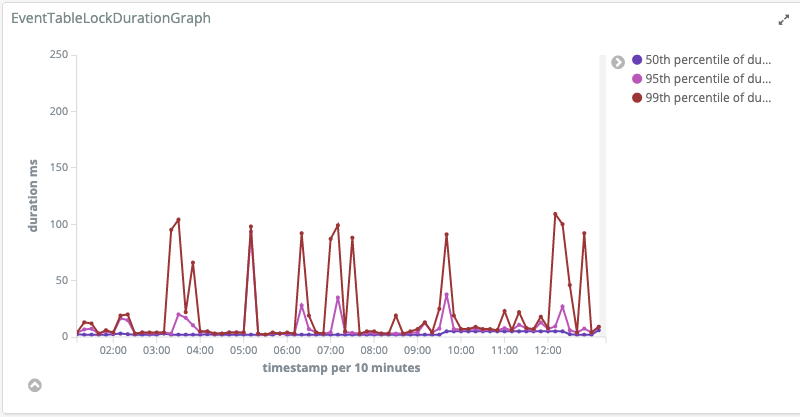
There is still room for improvement, such as not reading the actual data inside the lock, but only reading the highest inserted event identifier. After this we can fetch the actual data outside of the lock. That should lower the duration we need a lock and increase performance a bit, but currently performance is not a bottleneck.
Using lambdas with a database
One of the biggest downsides of using PostgreSQL together with lambdas is that you need to put the PostgreSQL in the same VPC as the lambdas. With lambdas you generally don't want a VPC because it adds 10 seconds to the cold startup time of the lambda. In production this turned out not to be such a problem, as most of the time a warm lambda is hit, but it is still there. We didn't attempt to warm lambdas to prevent this problem.
Also, the promise of lambas is scaling back to zero if nothing is running. This should reduce cost since you don't need a dedicated VM to be up 24/7. But with a database, an elasticsearch cluster to hold our logs, it was not really cheaper or much easier than running the whole thing on a small Kubernetes cluster.
Unleashing the real potential
We’re quite happy that we decided to use event sourcing. Although there were some challenges to get it right, it was a joy to work on.
As event sourcing helped us to split things up pretty clearly into small substeps with no side effects, everything was very easy to unit test. Input and output were clearly described by TypeScript types and it was quick and easy to write tests for all substeps. It was straightforward to keep the code coverage very high. Since we’re handling payments and subscriptions, we felt tests were a must-have. It felt great that it was so easy to write them!
Another effect was that logging was a bit easier to implement in a very structured way. Piping those logs into a Kibana instance we were able to create a nice logging dashboard and statistics from this. This made monitoring things simple and gave us a lot of confidence in the performance of the system right from launch.
With tests, logging and a dashboard in place, we quickly spotted issues and edge cases. Fixing those felt a bit like time traveling. You fix the logic, rerun the projections based on the events and everything just falls into place like the bug was never there. Since we saved all relevant data in the events we did not run into cases where we couldn’t fix something, because we didn’t have the data anymore.
Building new features and business rules is just as easy. It’s also nice to be able to do a new projection alongside the current one and then have the statistics show how many users are impacted by the change and in what way.
This amount of control provides much needed agility to a system that can easily become something that no one dares to touch after a while. Especially since mistakes made in the projection logic are always recoverable. As long as the events are intact, you’re good to go!
Event sourcing: worth the headache if you need it
For simpler systems we wouldn’t recommend using event sourcing, but more complex systems where mistakes have big impact, such as payment systems, it’s a great fit.
Payment processing is hard to get right, especially when multiple payment service providers are involved. Using event sourcing doesn't make it easier. In fact, it introduces some hard problems like processing events in the right order, making sure no information outside of the event itself is used and taming AWS Lambda.
However, there is a great reward waiting for you once it is running smoothly: you have a transparent system in which you can explain perfectly why a customer is in a certain state and you’re able to correct bugs and mistakes after the fact. This gives unprecedented control and certainty.
Do you need to show how your software reaches a certain state? Is it important to be able to fix calculations after the fact? If so, consider event sourcing. It truly is the power tool you need.
Are you a backend developer who loves such complex challenges? Check out our job vacancies at werkenbij.q42.nl.